go back (07.13.05/08.23.2008)
 DrTim homepage link
DrTim homepage link
Fundamentals of Modern Statistics Samples and Regression
by Timothy Bilash MD MS OBGYN
July 2005
www.DrTimDelivers.com
based on the book:
FUNDAMENTALS OF MODERN STATISTICAL METHODS
Substantially Improving Power and Accuracy
Rand R. Wilcox (2001)
-----a unique source for understanding the basis of these methods that is well worth reading
Chapter One - Introduction
(p1-8)
- Inferential Methods
- Fundamental goal in statistics is to make inferences (assertions) about a large population from a sample subset, especially using small sample size,
and in turn whether the population parameters represented by the sample statistics reflect the typical individual. Elements of subjective interpretion are always present in this process.
TDB note: An additional goal in medicine is whether the typical individual represents the patient.
Physicians practice clinical medicine (clinical-medical significance), where statistics is just one of the pieces
used to diagnose and treat. "Evidence-based medicine", in contrast, presumes that all individuals are represented by the same sample statistic without judgements about individual variation.
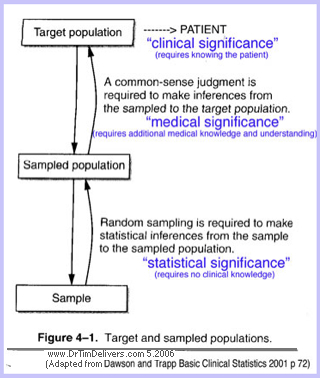
- Implication vs Inference [ANOTE]
- distinguish Uni-Directional from Bi-Directional causality.
- Uni-Directional Causation is an Implication Forward or Inference Backward
, when a risk implies forward or an outcome infers backward (one without requiring the other, not both).
- Bi-Directional Causation is an Equality,
when a risk implies and an outcome infers from both directions (one requires the other).
- These causalities are often confused. The truth of an inverse implication (inference = true)
is not equivalent to the forward implication(implication = true). It is more likely true unders some circumstances, but does not have to be, and is a common fatal error of circular logic and decision making.
- Normality
- Jacob Bernouli and Abraham de Moivre first developed approximations to the normal curve 300 years ago (p3-5)
- Further development of the normal curve for statistics by Laplace (random sampling) and Gauss (normal curve assumption)
- Gauss assumed the mean would be more accurate than the median (1809)
- showed by implication that the observation measurements arise from a normal curve if the mean is most accurate
- used circular reasoning though: there is no reason to assume that the mean optimally characterizes the observations. it was a convenient assumption that was in vogue at the time, since no way was clear to make progress without the assumption.
- Gauss-Markov theorem addresses this
- Laplace & vGauss methods were slow to catch on
- Karl Pearson dubbed the bell curve "normal" because he believed it was the natural curve.
- Practical problems remain for methods which are based on the normal curve assumption
- Another path to the normal curve is through the least squares principle. (p5-6)
- does not provide a satisfactory justification for the normal curve, however
- although observations do not always follow a normal curve, from a mathematical point of view it is extrememly convenient
- "Even under arbitrarily small departures from normality, important discoveries are lost by assuming that observations follow a normal curve." [p1-2]
- poorer detection of differences between groups and important associations among variables of interest if not normal
- the magnitude of these differences can also be grossly underestimated when using a common strategy based on the normal curve
- new inferential methods and fast computers provide insight
- Pierre-Simon Laplace method of the
Central limit theorem
(1811-1814)
- Prior to 1811, the only available framework for making inferences was the method of inverse probablility (Bayesian method). How and when a Bayesian point of view should be employed is still a controversy.
- Laplace's method dominates today, and is based on the frequentist point of view using confidence intervals for samples taken from the population (how often a confidence interval around a sample value will contain the true population value, rather than how often an interval around the true population value will contain the sample value).
- Laplace's method provides reasonably accurate results under random sampling,
provided the number of observations is sufficiently large,
without the need for an assumption of normality
in the population.
- Laplace method is based on sampling theory. It assumes that the plots of observation means for samples taken from the population have a normal distribution. It is a sampling theory.
- homogeneity of variance is an additional assumption often made, violation of which causes serious
problems
Chapter Two - Summary Statistics (p11-30)
- Seek a single value to represent the typical individual
from the distribution
- Area under a probability density function is always one
- Laplace distributions example (peaked discontinuous slope at maximum)
- many others
- Probability curves are never exactly symmetric
- often a reasonable approximation
- asymmetry is often a flag for poor representation by mean
- Finite sample breakdown point of sample statistic
- an outlier is an unusually large or small value for the outcome compared to the mean
- breakdown point quantifies the effect of outliers on a statistic
- breakdown point is the proportion of outliers
that make the sample statistic arbitrarily large or small (number out of n points, see below)
- Mean
- mean is the simple average of the sample values (ybar)
- ybar =
SUM
[yi]/n
- mean is highly affected by outliers.
- extreme values (Outliers) dominate the mean.
- a single outlier
can cause the mean to give a highly distorted value for the typical measurement.
- arbitrarily small subpopulation can make the mean arbitrarily small or large
- has smallest possible breakdown point (1/n). 1 observation or a single point can dominate the mean. it is the most affected by outliers which is not desireable, and why average is easily biased.
- Weighted Mean
- each observation is multipled by a constant and averaged
- any weighted mean is also dominated by outliers
- sample breakdown point of weighted mean
(1/n) is same as for mean (if all weights are different from zero).
- Median
- involves a type of "trimming ", or ignoring contributions of some of the data
- also orders the observations (which invalidates many statistical tests because violates random sampling)
- eliminates all highest and lowest values to find the middle one
- has highest possible breakdown point (1/2). n/2 observations needed to dominate the median, the least affected by outliers (desireable)
- Variance
(p20-22, 59, 246)
- A general desire in applied work is measuring the dispersion or spread
for a collection of numbers which represent a distribution.
- More than 100 measures of dispersion have been proposed
- Variance is one measure of the spread about the mean
- Population Variance = σ
2
- average squared deviation from the population mean for single observation (p245)
- σ
2 = SUM
[(population value - population mean)2 * (probablity of value)] = expected value
of σ
2
- s
= SQRT
[
σ
2] = Population Standard Deviation
of an singleobservation from the population mean
- convenient when working with the mean
- the Population Variance &sigma (for all in the population) is rarely known in practice, but can be estimated by the Sample Variance S of observations in a sample from that population (see below)
- Sample Variance
= S2
- the average squared deviation from the sample mean for single observation (p21, see below)
- S2 = SUM
[dev]2/(n-1) = SUM(
[sample observations-sample mean]2)/(n-1)
- S2
= [(y1-ybar)2
+ ... + (yN-ybar)2] / (n-1)
- Technically distinguished One Sample Mean from Many Sample Variance, calculated as the squared deviation from the Grand Mean. For normal distributions, the Many Sample Variance is the sum of the single sample variances.
- n = # in sample, n reduced to (n-1) to adjust for endpoints (independent degrees of freedom)
- (y-ybar) = deviation for a single observation in a sample from the sample mean
- Sample Variance refers to a Single Sample Variance (SSV). The combined Variance for Many Samples is also called the Sample Variance, and one is an estimate of the other.
- Breakdown point of the Sample Variance is the same as for the Sample Mean (1/n)
- a single outlier can dominate the value of the Sample Variance S2
- low breakdown point of the Sample Variance is especially devastating for determining significance, even when observations are symmetrically distributed around some central value.
- Variance of the Sample Mean = σ
2/ n
- approximates the average squared deviation from the population mean for sample means (p39,71)
- variance of the normal curve that approximates the plot of the sample means from the Population
- it is centered about the Population Mean, and depends critically on the independence of observations
- also calledSquared Standard Error of the Sample Means (SSEM) or Mean Squared Error (MSE)
- Standard Error of the Sample Mean (SE or SEM) = SQRT
[
σ
2/ n]
- Square root of the Variance
- n = # in sample
- measures precision of the sample mean
- for normal distributions, also measures accuracy of the sample mean, the closeness of Sample Mean to the Population Mean (makes the sum of the squared Standard Errors equal the square of the summed Standard Errors)
- Estimating Population Parameters by Sample Statistics (p59, also see ahead)
- Population Mean (µ) is estimated by (ybar) the Sample Mean (also by the Grand Mean)
- Population Variance (
σ2
) is estimated by ( S
2
) the Sample Variance for an observation (single sample)
- Population Standard Deviation (
σ = SQRT[ σ 2
]
) is estimated by (S = SQRT
[S2]), the square root of the sample variance
- Population Variance of the Sample Mean (
σ
2/ n) is estimated by ( S2/n ), the Single Sample Variance divided by the number in the sample (the single Sample Estimate of the Variance)
- The terms mean, variance and standard deviation are confusingly used for both population parameters and sample estimates. The distinction between a population parameter (which is a fixed number) and the sample statistic that estimates it (which is a function of the sample) should always be kept in mind. (Mandel p43)
- Estimates of statistical closeness of fit (precision) (p22-24)
- Absolute Value Principle (Boskovich 1700)
- calculate the error for value that minimizes the sum of the absolute value errors
- uses median value
- sample median minimizes the sum of absolute errors
- Least Squares Principle (Legendre 1806)
- calculate the error for the value obtained that minimizes the sum of the squared errors
- uses mean values which minimizes the sum of the squared errors
- Gauss had used this method earlier but did not publish it until 1809
- There are are infinitely many other ways to measure closeness in addition to these
- essentially arbitrary which measure is used, so some other criteria must be invoked
- absolute value to a power
- M-estimators of location (Ellis 1844)
- >Sample Mean is a special case of M-estimators
- many others
- Fitting a Straight Line to Data (Principle of Regression p24-28)
- Background
- any two points (x1,y1), (x2,y2) can be used to determine the slope and intercept of a line
y= intercept + slope*x or (y2-y1)= intercept + slope*(x2-x1)
- overdetermined algebraic problem
- would get a different line for each pair chosen
- N points yields 2N estimates of the slope and intercept
- discrepancies are due in part to measurement errors
- Simple Linear Regression (one predictor, one outcome)(p28)
-
- measure only the linear relationship between the indendent and dependent variable
- use the descrepancy between a proposed line (predicted) and the data line (observed)
- descrepancy is called a residual
Residual = r = Y(observed) - Y(expected)
- Absolute Residual Method (Roger Boscovich 1700)
- minimize the sum of absolute residuals
- equivalent to finding the Median
- Least Squares Residual Method (Legendre 1809) (p28-30)
- unclear if Gauss or Legendre first to use least squares method
- minimize the sum of squared residuals, instead of absolute residuals
- estimated slope turns out to be a weighted mean of the Y values
- equivalently estimated slope is also a weighted mean of all the slopes
between all pairs of points
- when the slope is zero, the sample mean estimates the intercept
- emphasizes values farthest from the mean (a linear method)
- find the weighted mean from the infinitely many, which on average is the most accurate
- represents the slope and intercept if no measurement errors and infinitely many points
- weights are determined by the descrepancy of X-values (predictors) from the mean-X-value
- these weights sum to zero, not one
- a single unusual point, properly placed, can cause the least square estimate of the slope to be arbitrarily large or small. (breakdown point of 1/N for any weighted mean)
- Multiple Linear Regression (two or more predictors/risks, one outcome)
- predictor independent variables can be numerical or nominal
- outcome dependent variables must be numerical only and cannot be nominal
- measures only the linear relationship between the independent and dependent variables
- there is ambiguity about the term multiple regression. some use the term for
multiple outcomes, rather than multiple risks, or even both multiple outcomes and risks
- Gauss devised the method of elimination to handle multiple predictors
Chapter Three - Normal Curve and Outlier Detection
(p31-48)
- Represent the shape of population distribution by fitting a "normal" distribution to it
- Exponential of [minus the squared deviation from the population mean],
divided by [the average squared deviation ] (ie, normalized by the variance)
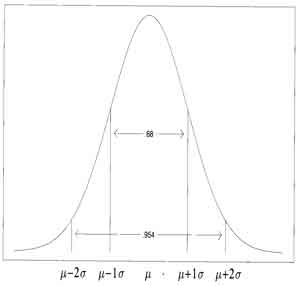
- 94% of observations are within 2 standard deviations, 68% of observations are within one standard deviation for a normal distribution
- Mean and Standard Deviation completely represent the distribution if it is normal. Probabilities are determined exactly by the mean and standard deviation when observations follow a normal
- Population Distribution versus Distributions of Samples taken from the Population
- Population
Distribution
- values for every member of the population
- summary parameters for population distribution (population mean and standard deviation as example)
- Sampling Distribution
- repeated, (hopefully) random observations collected in a sample
- sample is subset from total population (values for some members of the population)
- size (number n) in each sample
- "primary" statistics for each sample distribution (sample mean, sample standard deviation and sample variance as examples)
- Precision
- inferences about the sampling distribution (Statistics)
- how well sample values represent sample statistic (ie, spread about sample mean)
- can estimate precision from the sample data
- Accuracy
- Inferences about the population distribution from the sampling distribution (Statistics + Probablility)
- how well sample statistic represents population parameter (spread of single observations or means from sample of observations about the population mean), which depends on
- randomness of sampling
- size (number) in each sample (n)
- inferences using non-random sampling from the population may lead to serious errors.
- estimating accuracy from the sample data requires subjective inference in addition to estimating precision
- Mean, Variance, Standard Deviation for Means for Sample Distributions
- Sample Mean is a "primary" statistic from a single Sampling distribution
- Sample Variance for observations from a single sample is S2
- Sample Standard Deviation for observations from a single sample is S (square root of the Sample Variance)
- Mean of Sample Means (Grand Mean) is a "secondary" or summary statistic derived from the distribution of the Sample Means (statistic based on collection of statistics)
- Deviations of sample means from the average of sample means form a gaussian (normal) distribution if the samples are random
- Standard Error of the Sample Mean (SEM, SE, or Mean Squared Error) is the Standard Deviation for the Means of Samples , relative to a single sample mean (or average of all sample means, the grand mean) used as an approximation to the population mean
- Standard Error of the Sample Mean (SE) can be estimated from S as S2/n.
This indicates how close (related to percentage of all sample means) any one Sample Mean approximates the average Sample Mean, which both approximate the population mean (statistic + inference)
- S2
is the Standard Deviation Squared (SD2) for a sample observation (p21).
(n-1) is the divisor to calculate (S2) for Single Observations, from the squared deviations (residuals)
S2 also estimates the Variance of one observation about the Population Mean
- S2/n
is the Standard Error Squared (SE2), the Standard Deviation Squared for a mean of sample observations (approximate, S approximates σ) (p39)
(n) is the divisor to calculate (SE2) for Sample Means, from S2
S2/n also estimates the Variance of Sample Means about the Population Mean
- Median Absolute Deviation (MAD) Statistic
- Want measures of location
(representative value) and scale
(spread around that value) for a distribution, which are not themselves affected by outliers
- Median is one alternative statistic to using mean (middle value)
- MAD = median of the [absolute value of the (deviations from the median)] (computed from median of the deviations, see Median)
- MAD/.6745 estimates the population standard deviation
for a normal probability curve
- MAD is less accurate than the sample standard deviation S (computed from mean of the squared deviations) in estimating the population standard deviation
σ for a normal distribution
- Masking
- both the sample mean and sample standard deviation are inflated by outliers
- increasing an outlier value also increases the mean and standard deviation for that sample, masking the ability to detect outliers
- MAD is much less affected by outliers, so good for detecting outliers (sample breakdown point of 0.5, highest possible)
- Outlier Detection using MAD {approximation for |X-Median|
= 2.965*MAD
}:
|X-Median| > [3*MAD] to determine Outliers
- Central Limit Theorem
(for samples containing large numbers
- due to Laplace p39)
- Normal Curve
- plots of sample means approximately follow a normal curve, provided each mean is based on a reasonably
large sample size
- this normal curve of sample means would be centered about the population mean.
- spread in values obtained from one sampling
is called sample variance
- the variance of the normal curve that approximates the plot of the means from each sample (variation of the means of samples or SSEM) is estimated by (
σ2
/ n
) defined using:
- population variance (
σ2 )
- number of observations in a sample ( n ) used to compute the mean
- going in inverse order from inference here (use population to estimate the sample)
- distinguish SSEM of many samples from the Variance of one sample
- non-normality of the parent distribution affects the significance tests for differences of means
- there is no theorem to give a precise size for "reasonably large"
- Graphs of (left) Normal Distribution and (right) Medians (used here for illustration, similar to a plot from Means) (dots) of small-sized Samples from Normal Distribution with Expected Normal Distribution from mean and standard deviation (solid), for sample sizes of 20 (fig 3.2 p 34, fig 3.11 p45)
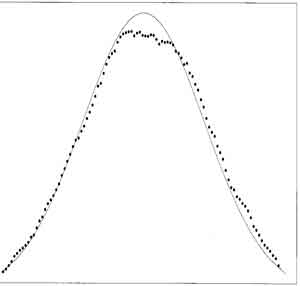
- [ISLT] curve characteristics relative to the normal curve determine the accuracy of summary statistics
- departure from standard bell shape (non-normality, small effect on mean )
- if deviations of dependent values (Y's)
- skew from symmetry (
bias,
large effect on mean)
- if asymmetry about the mean, one tail is higher than the other at the same distance from the mean
- tails at extreme values (
falloff,
large effect on mean and variance)
- if convergence slower than normal distribution
- summary statistics from non-normal distributions depend both on values in the distribution plus the rate of change in values (ie, second or higher derivatives, or amount of skew compared to normal curve)
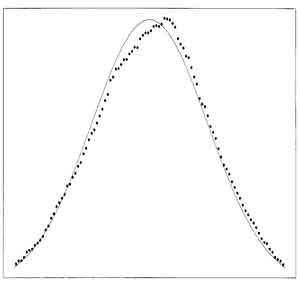
- Uniform
distribution
example (p40)
- constant value from 0 to 1 (all values equally likey, between 0 and 1, step function)
- population mean for this curve is 0.5
- population variance is 1/12
- light tailed and symmetric
- central limit theorem predicts that the plot of random small-sample means is approximately normal, centered around 0.5 mean, with variance 1/12N.
- plot of only twenty means of samples gives reasonably good results
(p40 example).
- multiple random sample of twenty values used to predict mean
- distribution of these small sample means skewed to slightly higher value
- Graphs of (left) Uniform Distribution and (right) Means (dots)of Small-sized Samples from Uniform Distribution with Expected Normal Distribution from mean and standard deviation (solid) (fig 3.5 p40, fig 3.6 p 41)
- Exponential
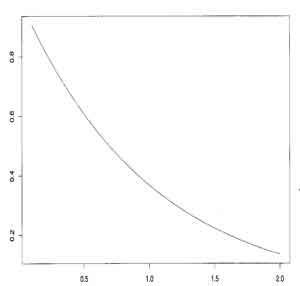
distribution
example (p40)
- exp(-x) or exp(x)
- population mean is 1
- population variance is 1/n
- light tailed and asymmetric
(small samples approximate the normal curve well)
- plot of means from samples of only 20 gives reasonably good results assuming the central limit theorem (random small samples of means approximates a normal curve)
- plot of means of small sample (n=20) is skewed to slightly lower values
for exp(|-x|) compared to large sample means (follows normal curve)
- [ISLT] means of small samples from exp(|x|) distribution
will be skewed to higher
values
- exp(-|x|) skewed to smaller
values, more so than for a uniform distribution (see p38-40)
- Confidence Intervals (CI) of small samples from exp(|x|) are decreased
- Confidence Intervals (CI) of small samples from exp(-|x|) are increased
- Graphs of (left) Exponential Distribution and (right) Means (dots) of Small-sized Samples from Exponential Distribution with (left) Expected Normal Distribution from mean and standard deviation [solid] (fig 3.7 p41, fig 3.8 p42)
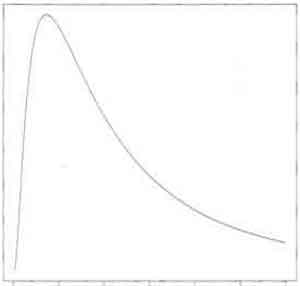
- Lognormal Distribution Example (p76)
- light tailed and highly asymmetric
- mean and median are not too far apart since light-tailed, but begins to have problems, especially with Variance estimates. see heavy-tailed "logheavy" below. T-distribution from lognormal begins to have problems because of this.
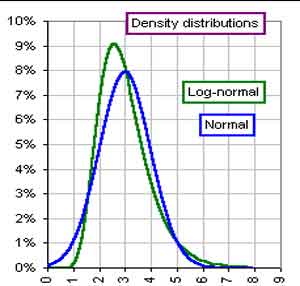
- Graphs of (left) Lognormal Distribution and (right) Means of Small-sized Samples from Lognormal Distribution (green) with Expected Normal Distribution from mean and standard deviation (blue) [from http://www.gummy-stuff.org/normal_log-normal.htm]
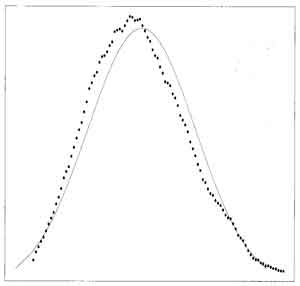
- "Logheavy"
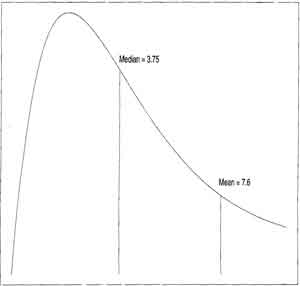
distribution
example
(p42)
- mean and median are very different (contrast with uniform and exponential, where mean and median are close)
- heavy tailed
and highly asymmetric
- outliers more common
- mean not
near the median
- distribution of sample means is poorly approximated
by the mean and standard deviation of the sample means
(normal approximation) for the "Logheavy" distribution
plot of means of small samples here are skewed to lower values, between the population median and the sample median, compared to large samples
- requires larger numbers for representation of central limit theorem normal approximation, approaching the population mean as the sample size increases.
- [ISLT] Accuracy of small samples for "logheavy" distribution
- skewing (assymetry relative to central tendancy), departure from linearity, and fall off towards infinity
all require larger numbers for normal approximation to be accurate (p44)
- high curvature decreases accuracy
- slower fall off towards infinity compared to normal distribution (outliers) decreases accuracy
- median is different from mean
- however, sample median still estimates the population median, even for skewed distributions
- small sample mean does not estimate the sample mean for skewed distributions since the mean and median are far apart (population mean far from most of the observations)
- faster drop and higher peaked below mean, compensated by slower drop and lower peak above the mean (see fig 3.10)
- contrast to lognormal distribution (light tailed)
- Graphs of (left) "Logheavy Distribution and (right) Means of Small-sized Samples from "Logheavy" Distribution (rippled) with Expected Normal Distribution from mean and standard deviation (solid) (fig 3.9, fig 3.10 p43)
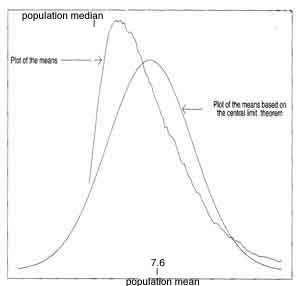
- ***"Logheavy" Distribution is much better approximated if use the Medians of Small-sized Samples to approximate population median instead of the Means to approximate population mean (see graph next and p46)
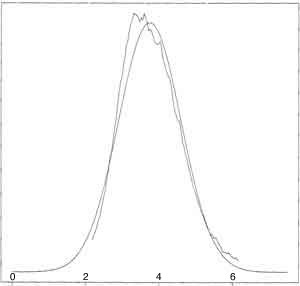
- Problems with Samples from Non-Normal Distributions: the Mean and the Median
- Tails (Light, Heavy)
- Tails are how quickly the probablity curve drops off
from the mean value towards infinite predictor (X)
- Uniform and Exponential
distributions are light tailed
(drop off quickly towards infinity compared to normal curve, outliers tend to be rare). However the Uniform Distribution is symmetric and Exponential Distribution is asymmetric.
- Logheavy distribution is heavy tailed and asymmetric
(drops off slowly towards infinity relative to the mean, outliers are common)
- [ANOTE]
I create terms for the distribution characteristic of "monotonicity"
(no change in sign of slope over distribution or wiggles in the distribution curve) and "logheavy" distribution, to be considered with the properties of symmetry
(reflection about the mean) and tails (falloff to large/small values) of a distribution
- Uniform distribution is .............
light-tailed, symmetric, monotonic (Fig 3.5 p40)
- Normal distribution is ..............
light-tailed, symmetric, non-monotonic (Fig 3.2 p34)
- Exponential distribution is .....
light-tailed, asymmetric, monotonic (Fig 3.7 p41)
- Lognormal distribution is ........ light-tailed, asymmetric, non-monotonic (Fig 5.3 p 76)
- "Logheavy" distribution is ...heavy-tailed, asymmetric, non-monotonic (Fig 3.9 p43)
- these greatly influence statistical behavior and accuracy (if more heavy-tailed, more asymmetric, and less monotonic, then less accurate). light-tails and symmetry are likely to give mean and variance approximations closer to the normal curve. a curve that approximates the normal as the relationship of outcome to predictor values would be called "normotonic".
- [ISLT] the combination of these three characterstics tails, symmetry and tonicity relative to the normal distribution curve determine the statistical precision and accuracy. Asymmetric, non-monotonic distributions appear to have unreliable means and/or variances for small samples.
- Accuracy of sample mean and median
(how close statistic is to parameter p44-45, fig 5.5 and fig 5.6 p79-81)
- for symmetric
probability curves (such as normal)
- medians and means of small samples center around the mean/median of a symmetric population
(since population mean and median are identical)
- normal curve is symmetric about the mean
- for asymmetric
probability curves
- mean
- means of small samples are closer to the population median, but
slowly converge to an asymmetric population mean as sample size increases, requiring larger sample size to estimate the population mean (p42)
- larger samples are needed using means than using medians
- this is due to the outliers (one outlier can completely dominate the mean)
- median
- medians of small samples center around the asymmetric population median
- sample median is separated from the asymmetric population mean (in general sample median is not
equal to the population mean. see "logheavy" distribution example)
- sample medians are a better approximation for the asymmetric population median, than sample means are for the asymmetric population mean with small samples.
- for light tailed
probability curves
- symmetric light-tailed curve- plots of sample means are approximately normal
even when based on only 20 values in a sample (p42)
- sample mean is close to the median and a good approximation to the population values for symmetric light tailed curves
- asymmetric light-tailed- curve can have poor probability coverage for the confidence interval, poor control over the probability of a type I error, and a biased Student's T
- for heavy tailed
probability curves
- symmetric
- [ISLT] sample mean is close to median and a good approximation to the population values, however the estimate of the population variance will be inaccurate for heavy-tailed symmetric curves
- asymmetric
- sample medians provide a better approximation for the population median, than do sample means for the population mean for heavy-tailed symmetric curves
- plots of sample means converge much more slowly to the mean for heavy- than light- tailed asymmetric distributions (p45)
Chapter Four
- Accuracy and Inference
(p49-66)
- Errors are always introduced when use a sample statistic (eg, mean for some individuals from the population) to estimate a population parameter (mean for all individuals in the population)
- can calculate the mean squared error of the sample means (average squared difference)
- average or mean of the squared [differences between the infinitely many means of samples (sample means) and the population mean]
- called the "expected squared difference" (expected denotes average)
- want the mean squared error to be as small as possible
- if the mean squared error for the sample mean is small, it does not imply that the standard deviation for a single observation will also be small.
- variance of the means of samples is called the squared standard error of the sample mean.
- Gauss and Laplace made early contributions for estimating the errors
- distinguish the sample mean deviation relative to the mean of sample means
vs relative to the mean of the population
- sample deviations vs population deviations
- sometimes these are the same depending on the distributions, and often used interchangeably:
standard deviation of the mean for a sample
standard error of the sample mean (standard deviation of the mean of all the sample means)
standard deviation of the mean for a population
- Weighted Means
- LARGE SIZE, Random Samples
(Laplace - Central Limit Theorem)
- under general conditions, the central limit theorem applies to a wide range of weighted means
- as the number of observations increases, and if repeated the experiment billions of times, would get fairly good agreement between the plot of weighted means and normal curve (can use the mean and standard deviation to estimate the curve)
- under random sampling and large numbers, most accurate estimate
of the population mean is the usual weighted sample mean.
each observation gets the same weight (1/N), based on the average square distance from the population mean.
- Assumptions
- assumes
random sampling
- assumes sample sizes are large
enough that the plot of means of the samples would follow a normal curve
- does not assume
that the samples were from a normal population curve
- does not assume
symmetry in the population curve
- SMALL or LARGE SIZE, Random Samples
(Gauss - General Sample Size)
- derived similar results under weaker conditions than Laplace, without
resorting to the central value theorem requiring large samples
- under random sampling
the optimal weighted
mean for estimating the population mean is the usual sample mean
(as for Laplace formulation). of all the linear combinations of the observations (
weighted means
) we might consider, the sample mean is most accurate
under relatively unrestricted conditions that allow the probability curve to be non-normal, regardless of sample size.
- Assumptions
- random sampling only
- does not assume
large numbers in sample
- does not assume
samples were from a normal population curve
- does not assume
symmetry
- used the rule of expected values
- there are problems with this approach for some distributions
- Median and other Classes of estimators
- These summary statistics are outside the class of weighted means
- Sample Median is sometimes more accurate
than the sample mean
- requires putting observations in ascending order, as well as weighting the observations
- Median vs Mean
- if probability curve is symmetric with random sampling,
can find a more accurate estimate of the population mean than the sample mean by looking outside the class of weighted means
- Mean
- sample mean is based on all the values
- nothing beats the mean under normality
- tails of the plotted sample means are closer to the central value than the median, so the sample mean is more accurate representation of the population mean
- [ANOTE] good for normal/symmetric distributions, otherwise unreliable statistic
- Median
- not a weighted mean
- can be slightly more or greatly more accurate in certain situations
- sample median is based on the two middle values
, with the rest of the values having zero weight
- median is a better estimate of the population mean for Laplace distributions (sharply peaked)
- (better for non-normal, symmetric distibutions)
- Regression Curve Fitting (Gauss-Markov Theorem) (p55)
- Simple regression (one predictor
variable X, one outcome
variable Y)
- least squares estimator of the slope/intercept of a regression line is the optimal among a class of weighted means
- does not rule out other measures of central tendancy
- "homoscedastic"
refers to a constant variance (i recommend the term convaried )
- population standard deviation (spread in outcome Y) is constant, independent of predictor variable risk X
- Gauss showed that if variance is constant, then the Least Squares estimator of the slope and intercept is optimal among all the weighted means
that minimize the expected squared error (expected denotes average)
- "heteroscedastic"
refers to a non-constant variance (i recommend the term non-convaried )
- population standard deviation or variation in Y values changes with predictor X
- Gauss showed that if the variance of the Y values corresponding to any X were know, then optimal weights for estimating the slope could be determined, and derived this result for multiple predictors as well
- many analysts used the unweighted least squares estimator, assuming a constant variance for the population. however, in some situations, using optimal weighting can result in an estimate that is hundreds, even thousands of times more accurate than the unweighted
- Estimating unknown population parameters
(making the chain of inference)
- Each individual is a member of progressively larger (more inclusive) groups
- individual sample contains a subset of individuals in the population
- sample of individuals drawn at random creates a kind of envelope or shape for the distribution which groups them together (sample curve)
- one individual can belong to many different sample groups of the population distribution (different sample curves drawn from the population curve)
- individual in the population is a member of the population
as well as a member of sample groups
- Progression for inference: individual, sample, finite group of samples, infinite group of samples, population
- An extended chain of inferences
is required for validity: individual
to sample
to finite number of samples
to
infinite number of samples
to population distribution
to individual in the population distribution (or mean of sample
to mean of finite samples
to
mean of infinite samples
to mean of population distribution
to individual in the population distribution)
- Parameter
reflects some characteristic of a population
of subjects
- Statistic
reflects some characteristic of a sample
from that population (primary, or summay secondary)
- want to approximate the probability that the population parameter (and thus individual) is reflected by sample statistic. a summary statistic
from the sample is used to estimate the corresponding population summary parameter
- When use a sample of individuals from the population to estimate the population parameter (for all individuals), always make an error
- large number n in each sample
requires the central limit theorem (number of samples N
)
- Ps
= sample estimate
of a population parameter
- SE(Ps) is the standard error of Ps (for number n in each sample) = σ/SQRT
(N) ~ S/
SQRT
(n).
Contrast the sample error of the mean from a single sample versus standard error of the mean for limit of infinite number of samples
- CI(Ps, 95%)
= CI(Ps, 95% Confidence Interval) = [Ps-1.96*SE(Ps)] to [Ps+1.96*SE(Ps)] which
has an approximate 95% probability of containing the unknown population parameter
- Estimating the Population Mean
(p58)
- Laplace General method
- requires random sampling, which means that all observations in a sample are independent of risks and outcomes
- plot of infinitely many sample means assumed to follow a normal curve. this is reasonable for:
- large numbers
in each sample (use central limit theorem)
- normal distribution
in population
- find an expression for the variance
of infinitely many sample means
- make a chain of inferences:
- find mean of one sample
- estimates the mean of many samples
- estimates the mean of infinite number of samples
- estimates the population mean
- Standard Deviation
***
- confusing terminology (implied by the context)
- sample mean refers to the average from one sample
, but also used for the average of the means from many (average from single sample vs average from multiple samples)
- SD (Standard Deviation)
can refer to spread in any collection of individual observations, for a sample,
for a population
it represents, and also within any grouping
- standard deviation for a sample of individuals from the population
(S using the sample mean)
- approximates the standard deviation of sample means from the grand mean
- approximates the population standard deviation σ
- Confidence Interval (Laplace 1814 p58)
- Confidence Interval for a Population Parameter Ps
- CI(Ps, 95%) = [Ps-1.96*SE(Ps) to Ps+1.96*SE(Ps)]
- Ps
= sample estimate
of a population parameter
- N = number in each sample
- SE(Ps) is the standard error of Ps
- has an approximate 95% probability of containing the unknown population parameter
- this method assumes homoscedasticity. if there is heteroscedasticity
, the confidence interval can be extremely inaccurate
,
even under normality.
- Confidence Interval
for the population
mean (µ)
(p60)
- assumes normal distribution
in population and large numbers
N in each sample
- population mean = (
µ)
- population variance = (σ
2)
- sample mean variance = (
σ 2
/ N
) is the squared deviations from
µ summed
- assumes sample variance ( S )
approximates the population variance (
large numbers
in samples, invoke central limit theorem)
- CI(µ, 95% population mean)
- the interval of +/-1.96 * [SE] = +/-1.96 * [
σ/
SQRT(N) ], has a 95% probability of containing the unknown population mean.
- This is an important point, for the confidence interval limits concern only the means of populations from which the samples are taken. The confidence limits are not bounds on a proportion of individuals from the population, and the projection to any individual requires inferences and judgements beyond the statistical analysis. In essence the population distribution must be known to do this.
- for large
enough samples, the sample approximation +/-1.96 * [S/SQRT(N)]
has an approximate 95% probability of containing the unknown population mean
- 95% confidence interval (CI) is used routinely for convenience. could be any other percentage also.
- Laplace routinely used 3
rather than 1.96
- Confidence Interval
(CI)
for the
slope
of a regression line
(Laplace p62-67)
- Linear Regression is a Weighted Mean (p46)
- repeat an experiment infinitely many times with N sampling points in each experiment
- Least Squares estimate of the slope of a regression line to the experimental (Y) results can be viewed as the weighted mean of the outcome (Y) values
. (see p28-30)
[ANOTE]
1) average of all values
vs average of means of all samples of values
is the same because linear (a+b)+c = a+b+c , if samples are random and numerous
2) normal distribution also makes the errors linear
- Laplace made a convenient assumption and hoped that it yielded reasonably accurate results
- assume large numbers
in each sample N (central limit theorem)
- assume constant variance
(homogenous or homoscedasticity, an important assumption
- if a reasonably large number of pairs of observations is used (Laplace), then get a good approximation of the plotted slopes under fairly general conditions
- [ANOTE] an experiment implies either a controlled selection or random selection
from all the possible selections, with identification and control of all variables
that may affect the result (are causative), for each observation, or group of observations, or some used function of the observations. defined selections gives results for a defined subgroup, random selections give results for average of random subgroup. these may or may not be equivalent.
- [ISLT]
its not the parent distribution, but the distribution of errors (for the mean) and square of errors (for the variance) that has to be linear and homoscedastic
- METHOD
for Least Squares
(p55-62)
- DEFINITIONS
for Least Squares
- y=b+ax
(theoretical regression line for the population we are trying to estimate)
- b
is the slope of the regression line for infinite number of points
- a
is the intercept of the regression line for infinite number of points
- n
is the number of data points
- Sy2
=
sample variance
of all the n number of sample yi
values from the sample mean
- yi
=bi
+ai
xi
(line fit for the ith sample data point, i=1 to n)
- (xi
,yi) is the ith data point
- x
i is the mean predictor value for the ith group
- yi is the mean outcome value for the ith group
- y=d+cx (arrived at regression line from that sample)
- d
is the least squares regression estimate of the intercept b for the n data points
- c is the least squares regression estimate of the slope a for the n data points
- ASSUMPTIONS for Least Squares
- assume
independence of outcome and predictor
- constant variance
in the population (homoscedasticity)
- determine that data does not contradict this assumption
- estimate this asssumed common variance (per Gauss suggestion)
- this assumption sometimes masks an association detectable by a method that permits heteroscedasticity
- RECIPE for Variance of the slope =
σc
2
for outcome results Y from Least Squares (p64)
- Var(Y) = Sy2 estimates the assumed common Variance of each group
- compute the Least Squares estimate of the slope
(a) and intercept (b) for the n points.
compute corresponding n residuals of the computed line from the data curve rn.
- square each n residuals
- sum the n results
- divide by the number of data pairs of observations minus two (n-2)
- Result For SLOPE VARIANCE for Least Squares (case of slope = c )
- Var(c) = σc
2 = squared standard error
of the least squares estimate of the slope c (p64)
computed using the common variance of the Y (outcome) values Sy2,
and the sample variance of the X (predictor) values
Sx2
- Var(c) = Sy2
/ [(n-1)*Sx2]
= ("squared
standard error of the least squares estimate of the slope")
- σc
= SQRT
[Var(c)]
= Sy
/ (
SQRT
[(n-1)*Sx2
])
= ("standard error of the slope")
- [ANOTE] squared error is linear for a normal curve
Chapter Five - Small Sample Size
(p67-91)
- these methods were developed over the last forty years
- originally thought that standard methods of inference were insensitve to violations of assumptions
- it is more more accurate to say that these methods perform reasonably well in terms of Type I errors, or false positive findings of statistical significance, when performing regression
- when groups have identical probability curves (shapes)
- when predictor variables are independent
- that is, can detect if two distribution curves are not identical, but dont know if it is because of a difference in means, difference in distribution shapes, difference in data errors, difference in some other charateristic of the distributions, or processing errors introduced into the distribution. And any comparison of summary data loses precision.
- due sampling differences
- due to population differences
- does this negate the ability to say that they are the same, or that they are not the same?
- Even worse problems arise if the regession variables are correlated. (p67)
- Hypothesis Testing
(p68-72)
- dicotomization method
- hypothesis testing dicotomizes the risk into a yes/no (for risk present/not) and outcome into a yes/no
(for test result correct/incorrect). it is based on choosing one predictor variable (risk)
and requires choosing null and alternative distributions.
there are also two error levels and two means for normal distributions, so also requires selecting an alpha error level
and a beta error level to dicotomize into 2 from the 6 parameters.
- choose null
(Ho)
and alternative
(Ha) hypotheses to provide a binary variable
(if null, then not alternative). since two parameters determine the assumed gaussian shape for each hypothesis distribution, picking two parameters forces a binary yes/no for comparing the means.
- there is much potential confusion, because of the use of multiple negations, and whether describe values relative to the null or relative to the alternative hypotheses
(either description is equivalent).
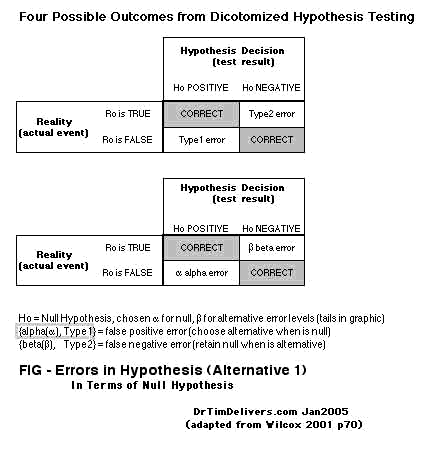
- DICOTOMIZATION allows for 4 possible Test/Reality Situations, often shown as a 2x2 table (see A):
Reality(R) is True .., Test(H) is Positive.. (
True... Positive, correct assertion)
Reality(R) is False , Test(H) is Negative (
True.. Negative, correct assertion)
Reality(R) is False , Test(H) is Positive.. (
False. Positive, type1 alpha error)
Reality(R) is True .., Test(H) is Negative (
False Negative, type2 beta error)
The actual Reality is not usually known, of course, which is the purpose of the test.
- There are equivalent ways to display the same hypothesis relationship, so careful attention is demanded to how the items are actually arranged. For example, the 2x2 table [A] can be equivalently diagrammed by reversing Reality and Hypothesis, row with column [B].
A(left), B(right)

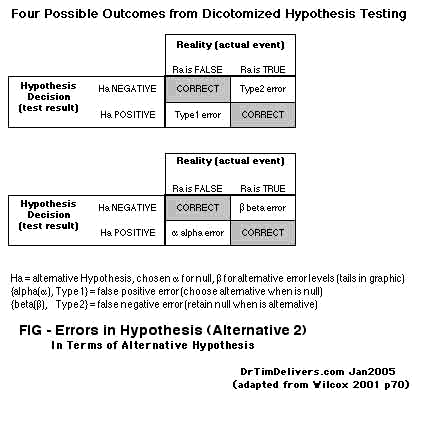
- Still more ways diagram the findings in terms of the alternative hypothesis, rather than the null hypothesis:
C(left),D(right)

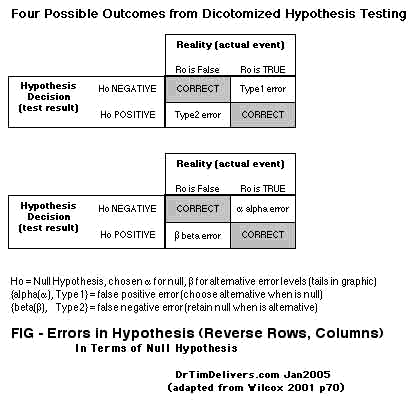
- The R0 & H0 can be interchanged within a row or column as well, and all the previous can be recast (shown here only for A as E):
E
- It is important to discuss the two statistical errors in hypothesis testing (mucho confusing terminology)
- Type I error
(see graphic of Hypothesis Testing below)
- alpha error, or "false finding"
of difference from expected null (here alpha is used interchangeably for the cutoff level and probability in the null tail)
- false discard/rejection of null assumption, a false positive
- discard the null and accept the incorrect alternativehypotheses, or erroneously not retain the correct null
hypothesis
(hypothesis testing implies two conditions not just one)
- acceptance of alternative caused by chance when populations are actually the same, populations seem different but are not (a Type I error)
- distribution for the null determines the probability of an alpha error for given alpha cutoff
- choosing an alpha cutoff level for the null distrbution also fixes beta, the chance might erroneouslyreject the false alternative hypothesis (for a given alternative distribution and a given null mean. the alpha cutoff for the null is the beta cutoff for the alternative.)
- Significance
(Null Probability related to alpha error)
- significance is how often correct when DO see effect
- determined by alpha cuttoff and null distribution
- true non-finding
, correct retention/acceptance of null, true-negative of a difference from expected null
- significance is (
1-alpha
) chance to correctly retain the true null hypothesis
- 95% null significance level (1-alpha) for a 5% Type I error level (alpha)
- Type II error
(see graphic of Hypothesis Testing below)
- beta error, or "false ignoring"
of a difference from expected null (here beta is used interchangeably for the cutoff level = Xc and probability in the alternative tail = function of Xc)
- false retention/acceptance of null, a false negative
- retain the null and reject the correct alternative hypothesis, or erroneously not discard the incorrect null
hypothesis (hypothesis testing implies two conditions not just one)
- retention of null caused by chance when populations are actually different, populations seem the same but are not (a Type II error)
- distribution for the alternative determines the probability of an beta error for given cutoff
- choosing a beta cutoff level for the alternative distribution also fixes alpha, the chance might erroneouslyretain the false null hypothesis, (for a given null distribution and alternate mean. the beta cutoff for alternative is the alpha cutoff for the null.)
- Power (Alternative Probablity) related to beta error
- power is how often correct when DO NOT see effect
- determined by beta cutoff and alternative distribution
- true finding, correct rejection/non-retention of null, or true-positive of a difference from expected null
- power is (1-beta) chance to correctly accept the true alternative hypothesis
- 95% alternative power level (1-beta) for a 5% Type II error level (beta)
- [IMPORTANT ANOTE]
- Technically, the null and/or alternative can be negated, which recasts the expected null as false and
alternative as true or whatever combination of the negations. These possibilities make craziness when following the logic of
hypothesis testing. I have cast the issue here in the one way only for clarity and sanity. But perhaps research results would
be much clearer if a standard approach was adopted and how one has to pay attention to this nitty gritty minutiae.
- If the observations are correlated, then the alpha and beta probablities are highly
inaccurate (not discussed here). this violates the random selection assumption of summary statistics and is an important factor
biasing results.
- Graphic Illustration of Hypothesis Testing Errors
Shows the 6 parameters that must be limited to 2
top graph
error probabilities [alpha1, beta1]
middle graph
error probabilities [alpha1, beta2] same alpha/beta cutoff, different alternate mean, same alpha & different beta probablilities
lower graph
error probabilities [alpha2, beta2] different alpha/beta cutoff, same alternate mean, different alpha & beta probabilities
[clic to enlarge]
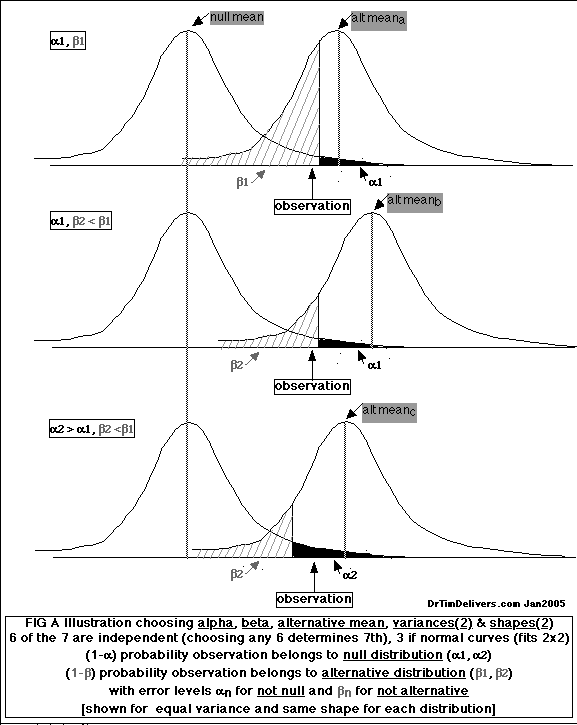
- Behavior of alpha significance, beta power
- error levels are always a compromise for given distributions and means - smaller alpha (fewer false positives) gives bigger beta (more false negatives), because they are not independent for fixed distributions
- smaller sample size
for a normal distribution gives lower power = (1-beta)
- smaller standard deviation
(variance of a distribution) gives higer power = (1-beta)
- Z Test
for significance with large sample size approximating a normal population distribution
- sample assumed from a normal curve
- standard deviation is known
- ymean is the sample mean
- µ is the population mean
- Z
= [
ymean - µ
]
/ [
σ/SQRT(N)
] has a normal distribution
- can rule out chances a specific
chosen value of the population mean µ, ie probablities are based on the mean of the alternative distribution
- Neyman, Pearson, Fisher developed (early 1900's)
- ok for large sample size N if population distribution approximates normal curve
- One-Sample Student's T test
used for significance with small samples and non-normal population distributions
- Laplace T distribution
(1814, for large sample size n, p72-74)
- Laplace T = (ymean - µ)
/
(S/
SQRT
[n])
- ymean is the sample mean
- µ is the population mean which is known
- problem if µ is not know
- Large sample size
- Laplace estimated the population standard deviation
σ with the sample standard deviation S
- assumed the distribution of sample means has a normal
distribution
- the difference between the population mean and the sample mean divided by the estimated standard error of the sample mean is normal,
with mean=0
and variance=1
- central limit theorem for large sample size (large N)
, T has a standard normal distribution with reasonably accurate probability coverage
- Small sample size
- Laplace T distribution is non-normal for small sample size N, even when sampled from a normal curve. using
Z probablilities does not provide a good estimate of the probabilities
for T distribution with small sample size
(see Colton p128)
- when sampling from light-tailed curve, the probability curve for the sample means is
approximately normal if the population distribution is not skewed (p74)
- if the distribution is skewed or heavy-tailed, large sample sizes are required
- Student's T Distribution
(William Gossett 1908)
(p74-76)
- T = (yi
-ybar) / ([S/sqrt(n)])
- yi = individual sample mean value
- ybar = (1/n)(y1
+y2
+...+yn
) = mean of all individual samples (Grand Mean of Sample Means)
- S2
= [(1/(n-1)]*[(y1
-ybar
)
2
+ ... + (yn
-ybar
)
2
] (Sample Variance for one sample)
- S/sqrt(n) = SE = SQRT
(S2)
- note uses ybar for µ
- extension
of Laplace T method, derived as approximation for the probability curve associated with T
- Ronald Fisher gave a more formal derivation
- probability depends on sample size
- assumes
normality and random sampling
- although it is bell-shaped and centered about zero, T does not belong to the family of normal curves
- (T) has a standard deviation larger than 1, compared to normal (Z) distribution which has a mean of zero and standard deviation of 1
- T and Z are both symmetric (see Dawson 2001 Basic and Clinical Statistics p99)
- there are infinitely many bell curves that are not normal
- for large sample sizes, the probability curve associated with the T values becomes indistinguishable from the normal curve
- most computer programs always calculate T instead of Z even for large sample size
- T~Z for sample size of 5 or larger
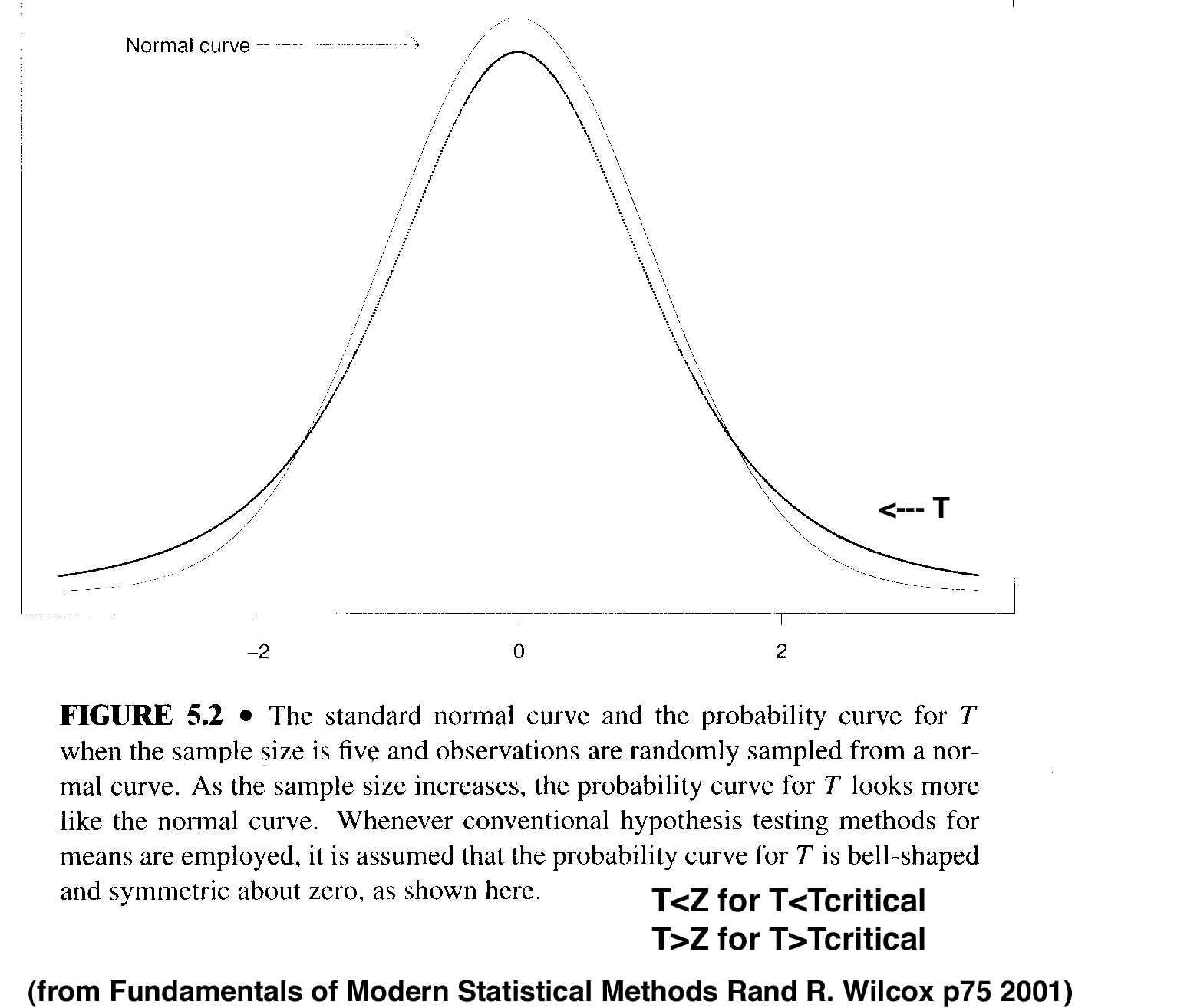
- for Tc<1.7, T < Z (T underestimates the probablity with 5 samples)
- for Tc>1.7, T > Z
>(T overestimates the probability with 5 samples)
- [ANOTE]
for a sample size of 5, calculating the Type I error (for alpha < .05 using Tc overestimates
the area beyond Tc compared to the normal curve for Zc = Tc.
- Practical Problems with Student's T
(p77-81)
- serious inaccuracies can result for some nonnormal distributions
- in general, the sample mean and sample variance are dependent
for T, that is the sample variance changes depending on the sample mean
- sample average for T is dependent on value and
slopes around that value
from the population distribution
- for normal curve mean and variance are independent
- Gossett's Student T can give exact confidence intervals and exact alpha Type I error for a normal
population distribution, regardless of small sample size
- When sample from a lognormal
distribution (example of skewed, light-tailed) actual probability curve for T differs
- plot of T distribution is skewed
(longer tail) to smaller T in this case, and not symmetric about the mean compared to sampling from normal curve, sample size twenty (Fig 3.9, 5.5)
- mean of T distribution is shifted to smaller T (skewed to longer-tailed side as well) compared to the population distribution mean, because the population mean for the log-normal is shifted higher. that is
- T is biased to smaller values (although median is not shifted in the same manner).
- Alpha error
can be inflated greater than the assumed level (underestimated). sometimes get a higher probability of rejecting when nothing is going on compared to when a difference actually exists
- Student T is then biased
- Expected Value E for the population of all individuals E[(Y-µ)2] = σ2
- Expected Value of the Sample Mean Ybar
is the population mean, or µ[E(Ybar
-µ) = 0]
- assumed
that T is symmetric about zero
(the expected value of T is zero, or the distribution of Y is symmetric about the mean) (p80)
- the Expected value of T must be zero if the mean and variance are independent, as under normality
- under non-
normality, it does not necessarily follow that the mean of T is zero
- for skewed distribution, estimating the unknown variance with the sample variance in Student's T needs larger sample sizes to compensate to get accurate results for the mean and variance even when outliers are rare (light-tailed), increased to 200 for this example from 20.
- the actual probability of a Type I (alpha error) can be substantially higher than 0.05
at the 0.05 level
- occurs when the probability curve for T differs substantially from curve assuming normality
- [ISLT] this is a problem when comparing distributions that are skewed differently. Bootstrap techniques
can estimate the probability curve for T to identify problem situations (Important newer techniques)
- Power
can also be affected with Student's T
(p82)
- the sample variance is more sensitive to outliers
than the sample mean for Student's T Distribution
- even though the outliers inflate the sample mean, they can inflate the sample variance more
- this increases the confidence intervals for the mean of the distribution, and prevents finding an effect (rejecting the null) when compare different distributions, lowering power.
- [ISLT] this more of a problem for power when T distribution is skewed
(distribution of means of samples from parent distribution), rather than when nonnormal and symmetric, or when the parent distribution is skewed
- evaluate symmetry of residuals for all sample means to check this
- implications of skewed vs heavy-tailed vs nonmonotonic (see ahead)
- Transforming the data
can improve T approximation
- simple transformations sometimes correct serious problems with controlling Type I (alpha)
- typical strategy is to take logarithms
of the observations and apply Student's T to the results
- simple transformations can fail to give satisfactory results in terms of achieving high power and relatively short confidence intervals (beta)
- other less obvious methods can be relatively more effective in these cases. sometimes have a higher probability of rejecting when nothing is going on, than when a difference actually exists
- Yuen's Method for difference of means (from Ch9)
- gives slightly better control of alpha error for large samples
- h is the number of observations left after trimming
- d1 =(n1-1)Sw1 2 / [h1(h1-1)]
- d2 =(n2-1)Sw2 2 / [h2(h2-1)]
- W = [(ymeant1 - ymeant2) - (µt1 - µt2)] / [SQRT(d1+d2)]
- adding the Bootstrap Method to Yuen's Method
may give better control of alpha error for small samples
- Welch's Test
is another method that is generally more accurate than Student's T
- Two-Sample Case for Means for significance with small samples
(p82-83)
Use Hypothesis of Equal Means
to obtain the Confidence Interval for Difference of Means
- Difference between sample means
estimates the difference between corresponding population means that samples are taken from
- LARGE
Sample Size
- Weighted
Two-Sample Difference
= W
- assume large sample size
(Laplace)
- assume random sampling
- no
assumption about population variances
- n1, n2 are corresponding sample sizes
- Population Variance for weighted difference is
- Var(ybar1
-ybar2) = (σ1)2/n1
+ (σ2)2/n2
- estimate this Population Variance with the Sample Variances (S1,S2)
- S2
= (S1)2/n1+(S2)2/n2
SE = SQRT
[S2]
= SQRT
[(S1)2/n1+(S2)2/n2]
- use the probabilities for the normal curve at 95%
- W = (ybar1-ybar2) / SE
or
W = (ybar1-ybar2) / SQRT[(S1)2/n1+(S2)2/n2]
- |W| > 1.96 = W.95 is the 95% confidence level to reject the hypothesis of equal means (from normal distribution)
- CI.95 = (W.95)*SE = (+/-1.96)*SQRT[(S1)2/n1+(S2)2/n2]
- get a reasonably accurate confidence interval by the central limit theorem and good control over a Type 1 (alpha) error (better than Two-Sample T) if sample sizes are sufficiently large
- W gives somewhat better results for unequal population variances, although this is a serious problem, especially for power.
- SMALL
Sample Size and Non-Normal
distribution
- Two-Sample Difference T
= T
- assume random sampling
(Student/Gossett)
- assume equal Population Variances
additionally
- n1, n2 are corresponding sample sizes
- For difference between sample means of two groups
- T = (ybar1-ybar2) / Sqrt[Sp2(1/n1+1/n2)]
where the assumed common variance is
Sp2
= [(n1-1)S12+(n2-1)S22] / [n1+n2-2]
- the hypothesis of equal means is rejected if |T| > t (cutoff t is a function of degrees of freedom df and the confidence level, and obtained from tables based on Student's T distribution)
- CI.95 = (t.95(df))*SE = (+/-t.95(df))*SQRT{[(n1-1)S12+(n2-1)S22] / [n1+n2-2]}
- W and T are equivalent for S1
= S2 (equal sample variances) or n1
= n2 (equal sample sizes)
- Student Two-Sample T
performs well under violations of assumptions
(p84)
- Student Two-Sample T
can substantially
avoid inflation of Type I (alpha) errors, if the probability distributions
- are normal
or have the same shape (ie, dont have differential skewness)
- have the same population variance
- have the same sample sizes
- then acceptable even for smaller samples
- Reliability of summary statistics for Two-SampleT
distribution is affected by the shape
and variance (of population or sample),
and size (for samples). Unequal variances or differences in skewness can greatly affect the ability to detect true differences between means. (p 85, 86,122)
1) same shape
- equal population variances
- alpha (Type 1)
error should be fairly accurate
- normal
or
nonnormal-identical shape distributions
- same or different sample size
- unequal population variances
- same sample size with normal
distributions
- sample size >8
, alpha (Type I)
error is fairly accurate
,
no matter how unequal the variances
- sample size <8
, alpha (Type I)
error can exceed 7.5%
at the 5% level
- same sample size with nonnormal
distributions, alpha (Type1) accuracy can be very poor
- different sample size with normal or nonnormal distributions, alpha (Type1) accuracy can be very poor
2) different shape
-
- alpha (type 1)
accuracy can be very poor
- nonnormal
and nonidentical
distributions
- equal and unequal population variance
/ same
and different
samples of any size
- Student T - Major Limitations
(p86)
- Student's T test is not reliable with unequal population variances
- Student's T test can have very poor power
(beta or false ignoring of effect,
larger confidence intervals) for unequal population variances
- exacerbated with unequal population variances
- any method based on means can have low power
- expected value of one-sample T can differ from zero, and power can decrease as the effect gets greater for one-sample T test (the test is biased)
- [ANOTE] power decreases (T<1.7) but begins to go back up (T>1.7)
- Student's T test does not control the probability of a Type 1 error
(
alpha or false finding
) for unequal population variances
- unequal distribution shapes, unequal variance, unequal sample size
can cause problems in that order
- unequal variances
with unequal sample sizes particularly can be a disaster for alpha error, even with equal sample sizes or normal distributions
- some argue that this is not a practical issue
- Difference between means may not represent the typical difference
for two-sample T, because is the difference of inaccurate estimates of the population means
- W
(Weighted T)
helps avoid this compared to
T
for larger sample size
- Transforming the distributions can improve variance properties
- logarithm
- sample median (not a simple transformation in that some observations are given zero weight)
- Rasmussen (1989) reviewed this, found that low power
due to outliers is still a problem
- When reject the null with Two-Sample Student T
(find a difference), it is an indication that the
probability distributions differ in some manner
(distributions are not
identical)
(p87-89)
- if the population curves differ in some manner other
than means, then the magnitude of any difference in the means becomes suspect (see limitations)
- population difference
- unequal means
- unequal variances
- difference in skew (shape)
- difference in other measure
- sampling difference
- unequal sample size
- non-randomization
- [ANOTE] a consideration is whether samples with equal sample variances would be likely to have unequal population variances,
and thus create a problem using the Student T. If a study factor changes the population distribution (as evidenced by a variance difference), Student T would have problems for the difference of means.
- The difference between any two variables having identical skewness is a symmetric distribution. With a symmetric distribution, Type I significance errors are controlled reasonably well. But if the distributions differ in skewness, problems arise. Even under symmetry however, power might be a serious problem when comparing means.
- [ISLT]
it is not so much that the population distributions themselves are skewed, but also factors which affect the derivatives of the distributions in different ways so that the difference curve is not symmetric (that is if skewing is not the same in both populations).
- normal curve
has symmetric (linear) derivatives at any point along the curve
- light tailed curves
would tend to have less problem (samples tend to be close to mean so symmetry is less of a problem)
- monotonic curves
would tend to have less of this problem (exp, step, linear, exponential - samples tend to be symmetric about the mean)
- heavy tailed skewed curves
have biased derivatives, so samples tend to favor one side of mean. also heavy tails would affect the variances even for symmetric curves.
- different population distributions would compare different biased means when determining differences (if the mean is biased the same way for in each group, when take the difference get accurate measure of difference of means)
The Bootstrap - Chapter 6*
- One of the most robust techniques of all for means and variances are newer Bootstrap Techniques
(a very important area not discussed here).
Trimmed Mean - Chapter 8
(p139-149)
- "There has been an apparent errosion in the lines of communication between mathematical statisticians and applied researchers and these issues remain largely unknown. It is difficult even for statisticians to keep up. Quick explanations of modern methods are difficult. Some of the methods are not intuitive based on the standard training most applied researchers receive."
- Issues about the sample mean (nonnormality)
- nonnormality can result in very low power
and
poor assessment of effect size
- cannot find an estimator that is always optimal
- problem gets worse trying to measure the association between variables via least squares regression and Pearson's correlation
- differences between probability curves
other than the mean can affect conventional hypothesis testing between means
- population mean and population variance are not robust; they are sensitive to very small changes for any probability curve
- affects Student's T, and its generalization to multiple groups using the so-called ANOVA F-test.
- variance of mean is smaller than variance of median for normal curve, but variance of mean is larger than variance of median for mixed-normal distributions, even for a a very slight departure from normality
- George Box
(1954) and colleagues
- sampling from normal distributions, unequal variances has no serious impact on the probability of a Type I (alpha) error
- if ratio of variances is less than 3, Type I (alpha) errors are generally controlled
- restrict ratio of the standard deviation of the largest group to the smallest at most sqrt(3)~2
- if this ratio gets larger, practical problems emerge
- Gene Glass
(1972) and colleagues, and subsequent researchers
- indicate problems for unequal variances in the ability to control errors
- if groups differ in terms of both variances and skewness get unsatisfactory power properties
(cant detect effects)
- H. Keselman
(1998)
- Summary of Factors affecting the probablities for the mean and variance
- nonnormality and
mixed normality
(nonnormal contamination of normal population distribution)
- small departures from normality can inflate the population variance tremendously
- heteroscedasticity,
or changes in variance with predictor (
σ2 ratio > 3 ,
σ ratio > 1.7)
- non-constant variance
- unless randomly affected rather than systematic
- skew
in population distribution
- asymmetry (very serious)
- heavy tailed population
distribution
- outliers dominate and can inflate the population variance tremendously
- differences between probability curve distributions
that are being compared
- M-estimator
and trimmed mean
can improve these problems
- M-estimators
- for symmetric curves can give fairly accurate results
- under even slight departures from symmetric curves, method breaks down especially for small sample size
- also applies to two sample case
- percentile bootstrap method performs better than percentile t method in combination with M-estimators for less than twenty observations
- Percent Trimmed Mean
[p143-149]
- General Trimmed Mean
- advantages of 20% trimmed mean for the very common situation of of heavy-tailed
probability curve
- sample variance is inflated
for heavy-tailed
compared to samples from a light-tailed distribution
- trimmed mean improves accuracy and precision for the mean
- tends to be substantially closer the the central value
- trimmed mean reduces the sample variance
compared to the sample mean
- more likely to get high power and relatively short confidence intervals
if use a trimmed mean
rather than the sample mean
- symmetric vs skewed
distributions does not affect this
- discards less accurate data that contaminates the population estimates
- for a normal curve
or one with light tails
, the sample mean is more accurate than the trimmed mean, but not substantially
- the middle values among a random sample of observations are much more likely to be close to the center of the normal curve.
- for the sample means, the extreme values hurt more than they help with even small departures from normality
- by trimming, in effect remove the heavy tails that bias the variance and thus the mean
- trimmed mean is not a weighted mean
and not covered by the Gauss-Markov theorem, since it involves ordering the observations
- when remove extreme values the remaining observations are dependent
- breakdown point
is 0.2 for the 20% trimmed mean
- the minimum proportion of outliers required to make the 20% trimmed mean arbitrarily large or small is 0.2 (20%)
- compare to the breakdown point of sample 1/n
for the mean
and 0.5 (50%)
for the median
- arguments have been made that a sample breakdown point <0.1 is unwise
- so sample mean is awful relative to outliers
- for symmetric probability curves, the mean, median and trimmed mean of the population are all identical
- for a skewed one, all three generally differ
- when distributions are skewed, the median and 20% trimmed mean are argued to be better measures of what is typical
(see Fig 8.3 p148)
- modern tools for characterizing the sensitivity of a parameter to small perturbations in a probability curve (since 1960)
- qualitative robustness
- infinitesimal robustness
- quantitative robustness (breakdown point of the sample mean for infinite sample size)
- Gamma%
Trimmed Mean
- Procedure
- determine
N, the number of observations
- compute
gamma*N (gamma= trim percentage)
- round
down to the nearest integer = g
- remove
the g smallest and g largest values (those with the largest deviations from the mean)
- average
the n-2g values that remain
- Example: 20% Trimmed Mean
(gamma=.2 or 20%)
- determine N, the number of observations
- compute
0.2*N
- round
down to the nearest integer g
- remove
the g smallest and g largest values (those with the largest deviations from the mean)
- average
the (n-2g) values that remain
Variance of the Trimmed Mean
- Chapter 9
(p159-178)
- Variance of the sample trimmed mean refers to the variation among the infinitely many values from repeating a study infinitely many times
- Computing the variance of the sample based on the data left after trimming
the sample mean, and the standard error of the mean by dividing this by the number of samples (as do in computing the sample mean) is not satisfactory
to obtain the trimmed variance
- usual variance of sample mean: if divide the sum of variables by n, the variance of the sum is divided by
n
- Var(ymean) = σ2
/ n
- the trimmed mean observations are not independent
(p162)
- the trimmed mean is an average of dependent variables and the sample mean method requires independence
- the variance of the sum of dependent variables is not equal to the sum of the individual variances, because the ordered variables are not independent
- want to find the situations where the sample trimmed mean has a normal distribution
- Estimating the sample trimmed mean, and variance of the sample trimmed mean
(p162)
- WINDSORIZE
rewrite the trimmed mean as the average of the independent variables
- COMPUTE
Windsorized Sample Mean (Windsorized Mean)
and the Sample Variance
of the Windsorized mean (Windorized Sample Variance)
- put the observations in order
- trim gamma*n = g observations hi/lo
(use Windsorized Variance)
- replace the trimmed values with the smallest of the non-trimmed values, so that the
g smallest values are increased to the g+1th value
not trimmed, and the g largest values likewise decreased (labled the W
n
)
- subtract
the Winsorized Mean from each of the Windsorized values, square
each result, and then sum
- divide by n-1
(number of observations-1) as when computing the sample variance s
2
- Windsorized Sample Mean
- ybarw = (1/n)(W1
+W2
+...+Wn)
- Windsorized Sample Variance
- Sw2
= [(1/(n-1)][(W1
-ybarw)2
+ ... + (Wn
-ybarw)2]
- ADJUST the area under the curve for trimming to sum to probability of 1
- Estimated Variance of the Trimmed mean
- Var(ybarT) = Sw2
/ (1-2
γ)2 n
- 20%Trimmed mean Estimated Variance
(
γ=.2, g=2, 1-2
γ=.6)
- Var(ybarT) = Sw2
/ (.36n)
SD(ybar
) = Sw
/ [.6
SQRT
(n)]
- Windsorized Variance for the trimmed mean is generally smaller
than the simple sample variance, because it pulls in extreme values that inflate S2
- trimmed mean will be more accurate than the sample mean when it has a smaller variance
- for very small departure from normality, the variance of the trimmed mean can be substantially smaller
- the trimmed mean is relatively unaffected when sampling from the mixed normal curve
- true even when sampling from skewed distributions
- division by (1-2
γ)2
could sometimes give the trimmed mean a larger
variance than the sample mean, as when sampling from a normal parent curve, but typically any such improvement using the mean instead of trimmed mean is small
- Standard Error of the Trimmed Mean
(estimate of the Population trimmed mean)***
- Small Sample Size (20% trimmed mean)
- Laplace Method approximation to the normal curve
- Tt
= (ybart
- µt) / [Sw
/.6sqrt(n)]
- CI = (+/-)tcrit(df)Sw
/ [.6sqrt(n)] = (+
/
-)SE
- approximates the curve for Student T where df = n-2g-1 (degrees of freedom)
- for small sample sizes, the smaller the effect of non-normality up to 20% trimmed mean (less so as trim more)
- improves rapidly as sample size increases
- γ=0.2, g=2, n=12 case
- n-2g-1 = 12-4-1 = 7
- for 20% trim with 12 degrees of freedom at 95% confidence, Tcrit
= 2.365, ie., T
t
>2.365 has probability <5%
- CI = (+
/
-) 2.365Sw/[.6sqrt(n)]
- 20% Trimmed Mean can be substantially more accurate than any method based on means, including the percentile bootstrap method
- indications are that can avoid alpha inaccuracies with sample sizes as small as 12 when combine the percentile bootstap method and the trimmed mean
- better control over alpha errors
- better power in a wide range of situations
- the problems of bias appear to be negligible (power decreasing as move away from the null hypothesis
- trimmed mean and sample mean are identical if sample from a symmetric population distribution
- if sample from skewed distribution, 20% trimmed mean is closer to the most likely values and provides a better reflection of the typical individual in the population
- confidence intervals for the trimmed mean is relatively insensitive to outliers (might be slightly altered when add the percentile bootstrap technique)
- does not eliminate all problems however, reduces them
- Power using Trimmed Mean versus Simple Mean
(p172)
- confidence interval for the difference between trimmed means is considerably shorter
than the confidence interval for the difference between sample means, because it is less affected by outliers
- even small departures from normality can result in very low power (ability to detect an effect)
- trimmed mean can reduce the problem of bias with a skewed distribution substantially
- it is common to find situations where one fails to find a difference with means, but a difference is found with trimmed means.
- it is rare for the reverse to happen, but it does happen
- More issues about Student's T
- how accurate the sample mean is for the population mean (estimates the population mean
), contrasted to how well the sample mean describes an individual in the population
(estimates the population variance
about the population mean)
- probability curve for T may not be symmetric around zero because of non-normality and asymmetry
- 20% trimmed mean with a percentile bootstrap
insures a more equi-tailed test, than when using a percentile T bootstrap with 20% trimmed mean
- when comparing multiple groups, probability of an alpha error can drop well below the nominal level, and the power can be decreased. switching to a percentile bootstrap method with 20% trimmed mean can address this.
- Percentile method using the 20% trimmed mean performs about as well as Student's T
when making inferences about Means.
- Percentile T method
works better than percentile method
in combination with the 20% trimmed mean as to shorter confidence intervals (Variances), and this improves for more than two groups
- theoretical results suggest that modifying the bootstrap method to Winsdorize before drawing bootstrap samples provides even shorter confidence intervals
Robust Regression - Chapter 11
(p206-228 selections)
- Least Squares Regression
- for probability of a Type I error (alpha error, seeing an effect that isnt there
) when testing the hypothesis of zero slope, least squares performs reasonably well.
- correlations between observations is a disaster for seeing an effect that isnt there (not discussed here)
- if want to detect an association (small beta
) and describe that association (small CI ), least squares can fail miserably
- heterodscedasticity
can result in relatively low power
when testing the hypthesis that the slope is zero
- single unusual point
can mask an important and interesting association
- nonnormality
makes this worse, and the conventional methods for the slope can be highly inaccurate
- when there is nonmormality or heteroscdedasticity, several additional methods
compete well, and can be strikingly more accurate than Least Squares
- Theil-Sen Estimator
- Least Absolute Value Estimator
- Least Trimmed Squares
- Least Trimmed Absolute Value
- Least Median of Squares
- Adjusted M-estimator
- newer Empiric methods
- Deepest Regression Line (still being developed)
- Using a regression estimator with a high breakdown point is no guarantee that disaster will be avoided with small sample sizes
- even among the robust regression estimators, the choice of method can make a practical difference
- a lower than max breakdown point may yield a more accurate estimate of the of the slope and intercept
- the example given (p 215) goes from a positive least squares estimate for slope (1.06, h=0 no trim), to a negative slope (-.62, h=.5n)
- using h=.8 (breakdown point =.2) gives a slope of 1.37
- for h=.75, gives a slope of .83
- Least median of squares estimate gives 1.36 (breakdown point of 0.5)
- Theil-Sen gives a slope of 1.01, which is more accurate than the least squares estimate
- Least Trimmed Squares
***
(p 212-215)
- Procedure for Least Trimmed Squares
:
- Ignore
(trim) the largest residuals when calculating the variance used in the least square estimate
- order the residuals
- compute the variance based on the h=çn smallest residuals
- with ç=.5
(h=.5n), the breakdown point is .5, but the smallest value of ç that should be used is n/2 rounded down to the nearest integer plus 1
- ç > Int(n/2) + 1
- choose slope b1 and intercept b0
that minimizes this reduced variance
for y=b0 +b1x line fit
- in effect by trimming them, removes the influence of the (n-h) largest residuals
- for h=.75n, ignores .25n in calculating the variance, so 25% of the points can be outliers without destroying the estimator
- [ISLT] the problem of highly inaccurate estimate of the population mean by the sample mean arises when the trim process changes the sign of the parameter estimate (eg, slope estimate for Least Squares).
- may be general principle that regression estimators break down when they have sign change from the untrimmed estimate (third derivative of the curve changes at places of zero slope, consider population distribution versus sample distribution)
- this is a principle when linear fitting a sharply curved plot (non-monotonic compared to normal curve)
- need to identify points of zero slope and inflection so that estimates are contained in a place that is monotonic around the actual value, and not skip over a max or min that takes the estimate further away
- graphical or other diagnostic tools appear instrumental to identifying these situations - graph the data!
- Regression Outliers and Leverage Points
(p217)
- Outliers
- regression outliers are points of the linear pattern that lie relatively far from the line
around which most points are centered
- one way is to determine them is to use the least median squares
regression line and compute the residuals using some criteria
- Leverage Points
- unusually large or small
X (predictor) values
are called leverage points
- these points are heteroscedastic
, with large residual (variance) for these large or small predictors
- good leverage point
is one that has a large or small predictor value (X)
, but is not a regression outlier
(residual of Y from fit is small, doesnt affect slope or variance)
- bad leverage point
is one that has a large Y residual for large or small predictor values (X)
, and grossly affects the estimate of the slope
- the effect of outliers can affect the variance in a different way from the mean
- bad
leverage points can lower the standard error
while affecting the slope more
despite the large (Y) residuals, since the larger the spread in predictor (X) values,
the lower the standard error (SE) despite any leveraged outliers. but this can be more than offset by the inaccurate estimate of the slope.
- "rogue outliers"
affect the slope less
and the variance more
by its leverage placement. y and x for the outliers are both inflated or deflated, so that Y/X keep close to the regression estimate although the variance is inflated.
Author Note about Sample Statistics
If the parent distributions don't really bunch around a central tendancy, are heavily skewed (bunched other than at the central tendancy) or are heavy-tailed, it is less accurate to use central tendancies to describe and compare them because the samples taken from those distributions can be biased.
The sample mean
describes a distribution well (and regressions to find that mean) when the observations bunch up around a symmetric central tendancy without outliers. When there are outliers, Trimming helps the remaining observations to more accurately bunch for comparisons
of means using the central tendancy. Differences of means for non-normal distributions are fairly reliable if the distributions have the same shape, but the probablities calculated from the Standard Error can be problematic.
"For example, the combination of the Percentile T Bootstrap and the 20 percent trimmed mean ... addresses all the problems with Student's T test, a result supported by both theory and simulation studies. The problem of bias appears to be negligible (power going down as the mean is further from the null hypothesis), we get vastly more accurate confidence intervals in situations where all methods based on means are deemed unsatisfactory, we get better control over Type I error probablilities, we get better power in a wider range of situations, and in the event sampling is from a normal curve, using means would offer only a slight advantage. When sampling from a probability curve that is symmetric, the population mean and trimmed mean are identical. But when sampling from a skewed curve [such as logheavy distribution], a 20 percent trimmed mean is closer to the most likely values and provides a better reflection of the typical individual under study." (p169)
The accuracy of probabilities and significance of differences depend on more than just the value of a central tendancy. The issue of comparing distributions that are skewed (same shapes or differing in shape) is a serious one, yet statistical techniques outlined here such as the trimmed mean, and newer bootstrap techniques (not discussed) offer powerful possibilities.
TDB
Top